

version 8.14
摘要:为破解大模型部署与推理成本高昂的困境,北京大学杨仝老师团队首次提出名为iFairy的超低比特量化方案。该方案创新性地利用复数{±1, ±i}对模型权重进行2-bit量化,在实现1/8极致压缩与“无乘法”推理加速的同时,语言建模能力和下游任务表现甚至反超了其全精度的LLaMA基座模型。
当下,大语言模型(LLM)的研究热潮席卷全球,技术迭代日新月异。然而,在这片繁荣之下,一个严峻的现实不容忽视:LLM在真实世界中产生的商业价值,很大程度上仍无法覆盖其高昂的训练与推理成本。
究其根源,大模型走向产业落地的道路上,横亘着两大“拦路虎”:空间瓶颈和时间瓶颈。
为了追求更高的模型性能,业界普遍的策略是不断堆叠参数量,这使得模型部署成本高昂。
同时,庞大的参数量带来了计算量的激增,尽管学界和业界已涌现出如gpt-oss的MXFP4训练等优秀的量化方案,但其核心计算逻辑依然没有消除对硬件资源消耗巨大的“乘法”运算的依赖,推理延迟没有实现根本性的降低。
能否同时攻克这两大瓶颈,实现模型的轻量化和推理加速,已成为推动大模型发展从“技术奇观”迈向“生产力工具”新阶段的关键。
为解决这一难题,北京大学杨仝老师团队在一篇名为“iFairy: the First 2-bit Complex LLM with All Parameters in {±1,±i}”的论文中,提出了一个脑洞大开的方案:跳出实数轴的束缚,进入复数平面!
这看似简单的维度提升,却蕴含着破解瓶颈的深刻智慧。
一、空间魔法:极致压缩,体积仅为1/8
在“空间”上,iFairy实现了极致的压缩。
传统的全精度(FP16)权重需要16比特,而iFairy方案仅用2比特,就完成了对一个权重信息的编码。
这意味着,相较于流行的FP16模型,其模型体积可以直接压缩至原来的1/8。这种“史诗级”的压缩率,为大模型在手机、汽车等边缘设备上的部署扫清了最大的存储障碍。
二、时间魔法:“无乘法”计算的革命
在“时间”上,iFairy实现了“无乘法”计算的革命。这个魔法是如何实现的呢?
1. PhaseQuant算法的神来之笔
这一切,都源于团队提出的全新量化算法PhaseQuant。它不再将权重映射到实数轴上的点,而是基于参数的相位将其映射到复平面上的四个单位根{±1, ±i}。
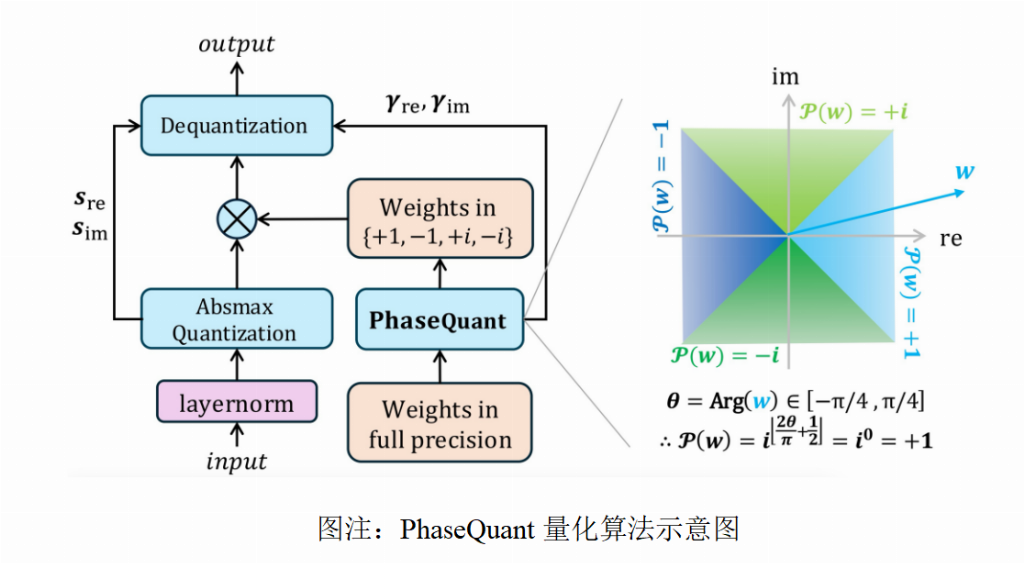
这一操作堪称神来之笔,一举多得:
信息密度拉满:用
{±1, ±i} 四个值,彻底利用了2-bit的全部信息容量,信息熵从传统三元量化(如BitNet b1.58)的log₂(3)≈1.58-bit,提升到满格的log₂(4)=2-bit。
优雅的对称性:这四个点在复平面上关于原点中心对称,保持了模型训练所需的良好性质。
隐含的稀疏性:每个量化后的复数权重,其实部或虚部必有一个为零,这在高维度上保留了稀疏性的优势。
2. 惊艳的“无乘法”运算
最令人拍案叫绝的是,引入复数,计算仍然高效!一个标准的复数乘法 (a+ib)(c+id) 需要4次实数乘法和2次加法,计算量不小。
但在iFairy模型中,当一个复数激活值与量化后的权重 {±1, ±i} 相乘时,运算发生了奇妙的“退化”:所有乘法都消失了。

看!整个模型中最核心、最庞大的矩阵乘法(GEMM),被彻底重构了!原本昂贵的浮点乘法运算,被完全替换为硬件成本几乎为零的加法、减法和数据交换(shuffle)操作。这从根本上消除了计算瓶颈,为实现数量级的推理加速提供了可能。
三、架构革新:一个全面“复数化”的Transformer
为了让这个魔法完美落地,研究团队还将整个Transformer架构都进行了“复数化”改造。
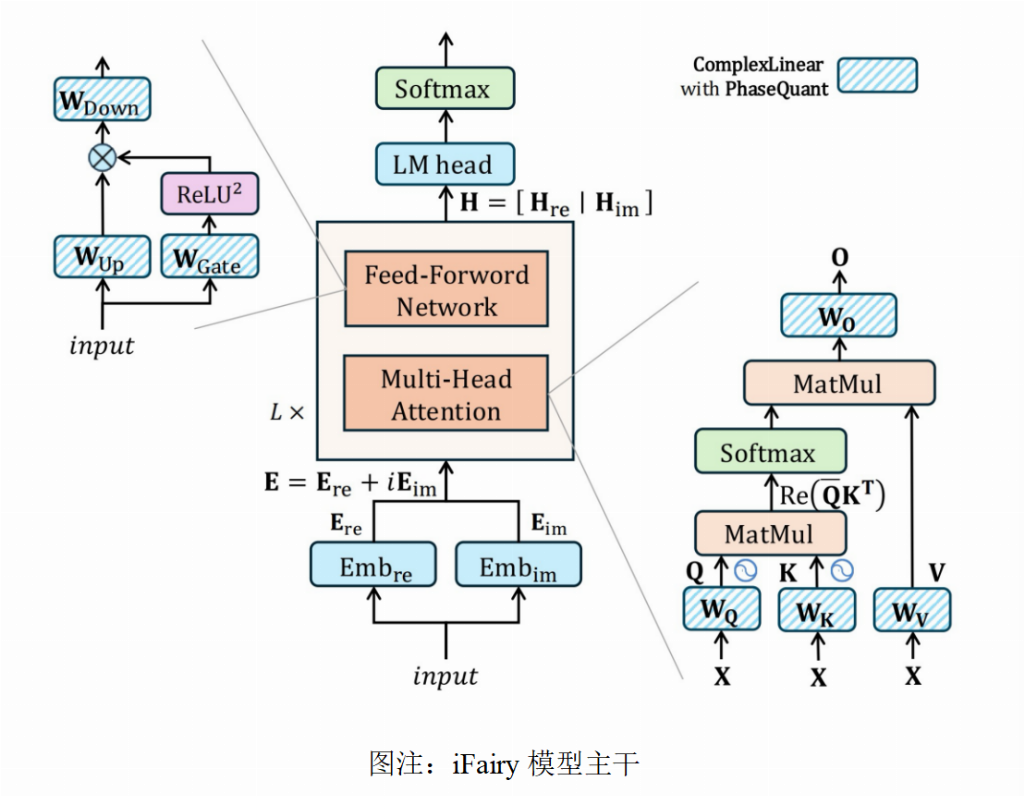
复数注意力机制:传统注意力计算Q和K的点积,这里则巧妙地使用了Hermitian内积的实部作为相似度分数,既利用了所有复数信息,又自然地得到了实数分数用于Softmax。
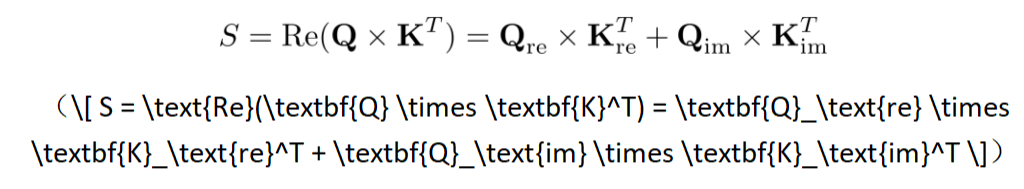
复数旋转位置编码(RoPE):在复数域,位置编码的旋转操作变得异常简洁和统一,一个简单的复数乘法即可实现。
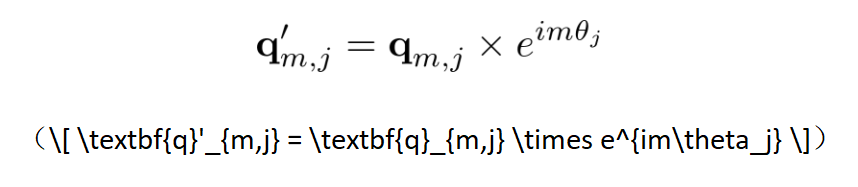
四、惊艳成果:PPL降低10%,性能反超全精度!
理论如此优雅,实践效果如何呢?结果同样令人瞩目。
iFairy 不仅没有出现超低比特量化常见的性能悬崖,反而实现了惊人的性能反超。
在LLM的语言建模能力方面,模型的困惑度(PPL)越低,代表模型对文本的理解和预测能力越强。在对PPL的测试中,基于相同数据集训练(注:为保证对比的严谨性,所有对比模型的训练数据均保持一致,具体信息可参见论文)的2-bit的iFairy 模型取得了比全精度(FP16)模型更低的困惑度(PPL),降幅高达 10%。
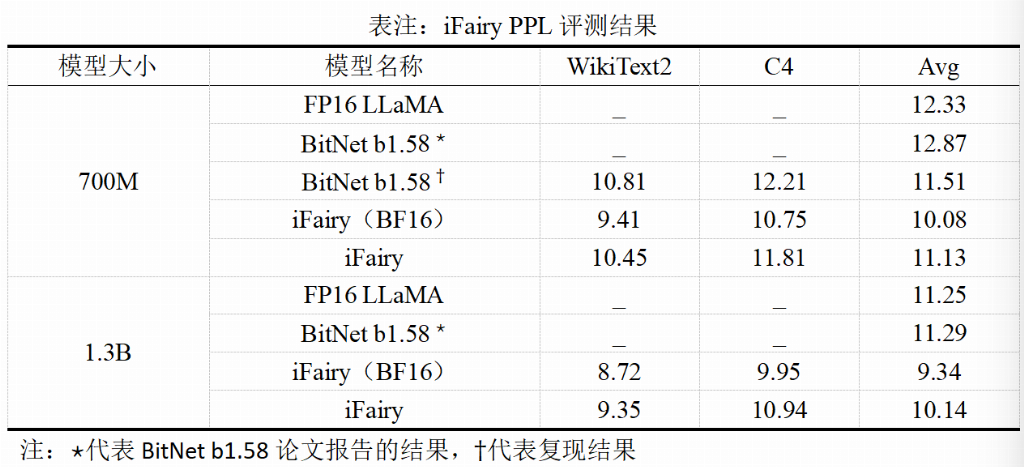
而在下游任务评测方面,iFairy 模型更是在多个任务的评分反超了全精度的Llama基座模型。
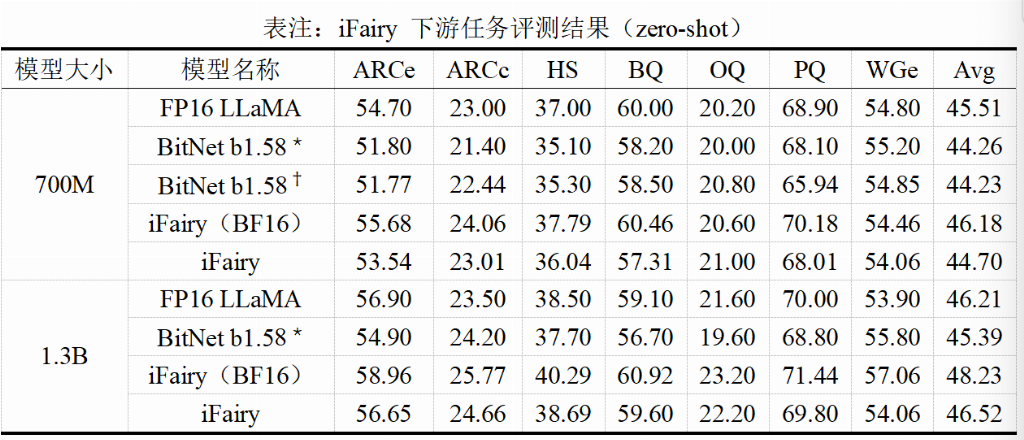
这意味着,一个体积只有原来1/8、计算几乎“零”乘法的模型,其能力反而更强了。这彻底颠覆了我们的传统认知。
对量化后权重的分析还发现,模型在训练后,这四个复数值 {±1, ±i} 的分布非常均匀,证明模型确实学会了充分利用这套全新的“编码系统”。
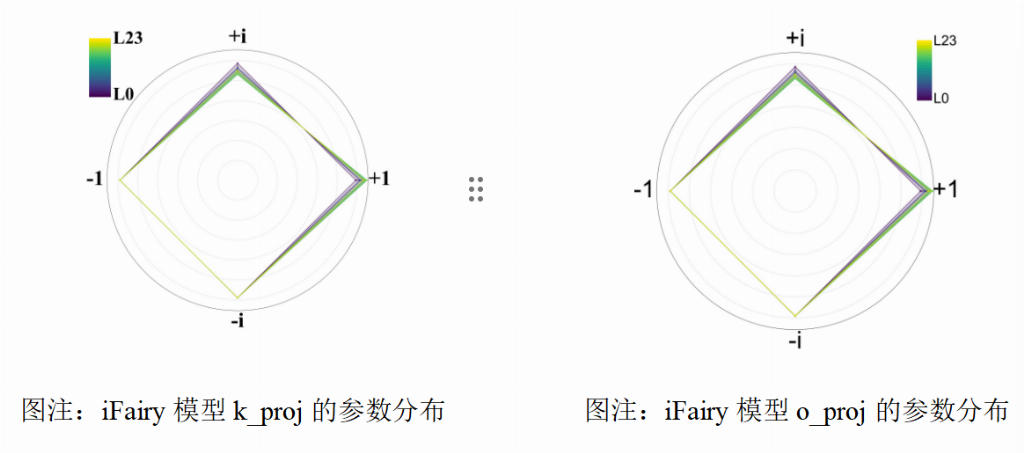
总而言之,这项工作开创性地将复数神经网络的思想与超低比特量化相结合,通过利用“相位”这一被忽略的信息维度,在不增加任何存储成本的前提下,显著提升了模型的表达能力和最终性能,真正实现了“鱼与熊掌兼得”。
它为设计下一代超高效、高性能的大语言模型,打开了一扇全新的大门。或许,我们离在普通手机上流畅运行GPT-5级别的模型,又近了一步。 相关论文、训练代码、模型权重与实验脚本已全部开源,配套提供从训练、评测到可复现实验的完整流程,人人皆可复现训练。



